
Deepseek Hopes and Goals
페이지 정보

본문
 Llama three 405B used 30.8M GPU hours for training relative to DeepSeek V3’s 2.6M GPU hours (extra data in the Llama 3 mannequin card). Many of those particulars had been shocking and extremely unexpected - highlighting numbers that made Meta look wasteful with GPUs, which prompted many on-line AI circles to roughly freakout. For Chinese corporations which are feeling the pressure of substantial chip export controls, it can't be seen as particularly shocking to have the angle be "Wow we are able to do method more than you with much less." I’d probably do the identical in their shoes, it is way more motivating than "my cluster is larger than yours." This goes to say that we need to understand how vital the narrative of compute numbers is to their reporting. We’ll get into the specific numbers under, however the query is, which of the various technical improvements listed within the DeepSeek V3 report contributed most to its studying effectivity - i.e. mannequin efficiency relative to compute used. Get the mannequin here on HuggingFace (DeepSeek). Get started with Mem0 utilizing pip. It’s a very capable mannequin, but not one that sparks as a lot joy when using it like Claude or with tremendous polished apps like ChatGPT, so I don’t count on to maintain using it long run.
Llama three 405B used 30.8M GPU hours for training relative to DeepSeek V3’s 2.6M GPU hours (extra data in the Llama 3 mannequin card). Many of those particulars had been shocking and extremely unexpected - highlighting numbers that made Meta look wasteful with GPUs, which prompted many on-line AI circles to roughly freakout. For Chinese corporations which are feeling the pressure of substantial chip export controls, it can't be seen as particularly shocking to have the angle be "Wow we are able to do method more than you with much less." I’d probably do the identical in their shoes, it is way more motivating than "my cluster is larger than yours." This goes to say that we need to understand how vital the narrative of compute numbers is to their reporting. We’ll get into the specific numbers under, however the query is, which of the various technical improvements listed within the DeepSeek V3 report contributed most to its studying effectivity - i.e. mannequin efficiency relative to compute used. Get the mannequin here on HuggingFace (DeepSeek). Get started with Mem0 utilizing pip. It’s a very capable mannequin, but not one that sparks as a lot joy when using it like Claude or with tremendous polished apps like ChatGPT, so I don’t count on to maintain using it long run.
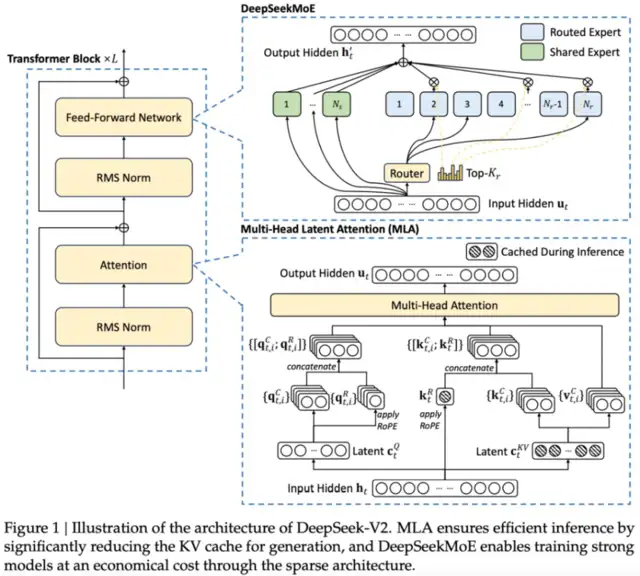 Essentially the most impressive half of those results are all on evaluations thought-about extraordinarily onerous - MATH 500 (which is a random 500 problems from the complete take a look at set), AIME 2024 (the super hard competitors math issues), Codeforces (competition code as featured in o3), and SWE-bench Verified (OpenAI’s improved dataset cut up). American A.I. infrastructure-each referred to as DeepSeek "tremendous impressive". As we glance ahead, the impression of deepseek ai LLM on analysis and language understanding will form the future of AI. By bettering code understanding, generation, and modifying capabilities, the researchers have pushed the boundaries of what giant language models can achieve in the realm of programming and mathematical reasoning. Flexing on how a lot compute you might have entry to is widespread observe among AI corporations. Common observe in language modeling laboratories is to make use of scaling legal guidelines to de-danger concepts for pretraining, so that you just spend little or no time coaching at the largest sizes that don't result in working models. Multi-head latent attention (MLA)2 to reduce the memory usage of attention operators whereas maintaining modeling efficiency.
Essentially the most impressive half of those results are all on evaluations thought-about extraordinarily onerous - MATH 500 (which is a random 500 problems from the complete take a look at set), AIME 2024 (the super hard competitors math issues), Codeforces (competition code as featured in o3), and SWE-bench Verified (OpenAI’s improved dataset cut up). American A.I. infrastructure-each referred to as DeepSeek "tremendous impressive". As we glance ahead, the impression of deepseek ai LLM on analysis and language understanding will form the future of AI. By bettering code understanding, generation, and modifying capabilities, the researchers have pushed the boundaries of what giant language models can achieve in the realm of programming and mathematical reasoning. Flexing on how a lot compute you might have entry to is widespread observe among AI corporations. Common observe in language modeling laboratories is to make use of scaling legal guidelines to de-danger concepts for pretraining, so that you just spend little or no time coaching at the largest sizes that don't result in working models. Multi-head latent attention (MLA)2 to reduce the memory usage of attention operators whereas maintaining modeling efficiency.
The technical report shares numerous particulars on modeling and infrastructure selections that dictated the ultimate final result. This submit revisits the technical details of DeepSeek V3, but focuses on how best to view the fee of coaching models on the frontier of AI and how these costs could also be altering. DeepSeek primarily took their current very good model, built a smart reinforcement learning on LLM engineering stack, then did some RL, then they used this dataset to turn their model and other good fashions into LLM reasoning models. Having lined AI breakthroughs, new LLM model launches, and skilled opinions, we deliver insightful and fascinating content material that retains readers informed and intrigued. Most of the methods DeepSeek describes in their paper are issues that our OLMo group at Ai2 would benefit from having access to and is taking direct inspiration from. The full compute used for the DeepSeek V3 mannequin for pretraining experiments would seemingly be 2-four occasions the reported number within the paper. The cumulative query of how much whole compute is utilized in experimentation for a model like this is way trickier. These GPUs don't reduce down the full compute or memory bandwidth.
These lower downs aren't able to be end use checked either and could potentially be reversed like Nvidia’s former crypto mining limiters, if the HW isn’t fused off. While NVLink speed are lower to 400GB/s, that's not restrictive for many parallelism methods which might be employed akin to 8x Tensor Parallel, Fully Sharded Data Parallel, and Pipeline Parallelism. The pipeline incorporates two RL stages geared toward discovering improved reasoning patterns and aligning with human preferences, in addition to two SFT stages that serve because the seed for the model's reasoning and non-reasoning capabilities. The AIS, very similar to credit scores in the US, is calculated using a wide range of algorithmic components linked to: question security, patterns of fraudulent or criminal behavior, traits in utilization over time, compliance with state and federal rules about ‘Safe Usage Standards’, and a wide range of other elements. Within the second stage, these consultants are distilled into one agent using RL with adaptive KL-regularization. The fact that the mannequin of this high quality is distilled from free deepseek’s reasoning mannequin collection, R1, makes me extra optimistic in regards to the reasoning model being the actual deal.
If you are you looking for more about deep seek take a look at our webpage.
- 이전글They Were Requested three Questions on How Much Do School Uniforms Cost In Australia... It is An awesome Lesson 25.02.01
- 다음글What Percent Of Schools Make Students Wear Uniforms On A Budget: 9 Tips From The Great Depression 25.02.01
댓글목록
등록된 댓글이 없습니다.