
Create A Deepseek You Might be Pleased With
페이지 정보

본문
 MoE in DeepSeek V3. Then, throughout inference, as a substitute of relying on a single huge mannequin to handle each domain of an issue, MoE will assign the query to the most capable knowledgeable fashions. Let's use an instance to easily perceive what MoE does. That's the same reply as Google offered in their instance notebook, so I'm presuming it's right. Throughout the training section, both the principle model and MTP modules take enter from the identical embedding layer. In essence, MLA compresses the input embedding dimension into its low-rank illustration by removing redundant parts. On this part, we'll focus solely on the attention layer, since that is the place the Multi-head Latent Attention (MLA) of DeepSeek V3 mannequin resides. In reality, it further advances the strategy with the introduction of MLA. Although it adds layers of complexity, the MTP approach is important for enhancing the mannequin's efficiency throughout different duties. As you will see in the following section, DeepSeek V3 is very performant in varied tasks with totally different domains equivalent to math, coding, language, etc. In truth, this model is currently the strongest open-supply base mannequin in a number of domains. Imagine we're studying at a university with many professors, every an professional in a special topic (math, physics, literature).
MoE in DeepSeek V3. Then, throughout inference, as a substitute of relying on a single huge mannequin to handle each domain of an issue, MoE will assign the query to the most capable knowledgeable fashions. Let's use an instance to easily perceive what MoE does. That's the same reply as Google offered in their instance notebook, so I'm presuming it's right. Throughout the training section, both the principle model and MTP modules take enter from the identical embedding layer. In essence, MLA compresses the input embedding dimension into its low-rank illustration by removing redundant parts. On this part, we'll focus solely on the attention layer, since that is the place the Multi-head Latent Attention (MLA) of DeepSeek V3 mannequin resides. In reality, it further advances the strategy with the introduction of MLA. Although it adds layers of complexity, the MTP approach is important for enhancing the mannequin's efficiency throughout different duties. As you will see in the following section, DeepSeek V3 is very performant in varied tasks with totally different domains equivalent to math, coding, language, etc. In truth, this model is currently the strongest open-supply base mannequin in a number of domains. Imagine we're studying at a university with many professors, every an professional in a special topic (math, physics, literature).
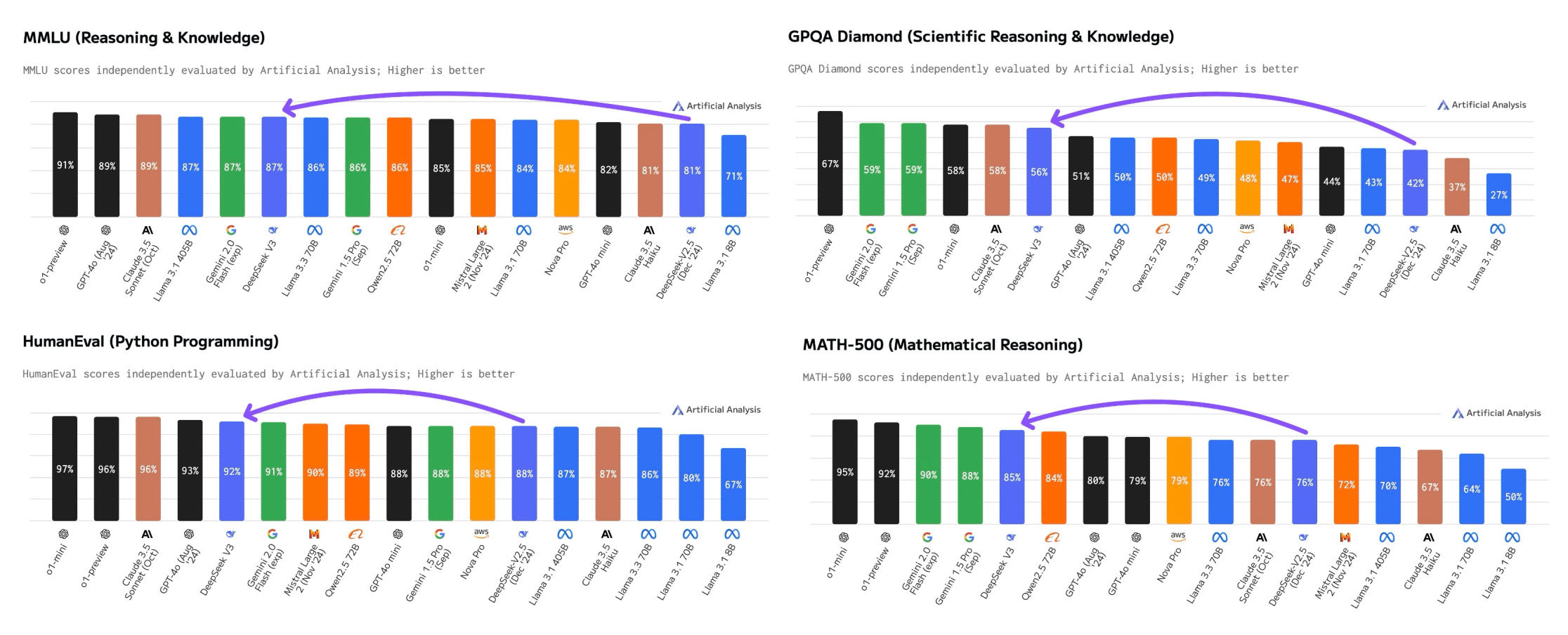
The University of Waterloo Tiger Lab's leaderboard ranked DeepSeek-V2 seventh on its LLM rating. Обучается с помощью Reflection-Tuning - техники, разработанной для того, чтобы дать возможность LLM исправить свои собственные ошибки. Our analysis outcomes demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on numerous benchmarks, notably in the domains of code, arithmetic, and reasoning. Compressor summary: The textual content describes a method to visualize neuron conduct in Deep Seek neural networks using an improved encoder-decoder mannequin with multiple consideration mechanisms, attaining higher outcomes on long sequence neuron captioning. The entire progressive features mentioned above enabled the DeepSeek V3 mannequin to be educated way more cheaply than its closed-supply opponents. GPT-four is 1.8T skilled on about as a lot data. We’ve already gone over some of DeepSeek’s privacy insurance policies and the information it collects. For Rajkiran Panuganti, senior director of generative AI functions on the Indian company Krutrim, DeepSeek’s beneficial properties aren’t simply educational.
While the company itself was launched in 2023, what made it a viral sensation was the launch of the DeepSeek chatbot powered by their R1 reasoning model. For example, the DeepSeek R1 mannequin is claimed to perform similarly to OpenAI's most superior reasoning model to this point, the o1 model, with solely a fraction of the training price. Recently, new LLMs developed by DeepSeek have generated massive hype throughout the AI group because of their performance and operational value mixture. In precept, this course of might be repeated to iteratively develop ideas in an open-ended vogue, appearing just like the human scientific neighborhood. Considered one of the top objectives of all Large Language Models (LLMs) we use these days is to be capable of understanding and performing any intellectual job that a human being can. Therefore, during the attention calculation of a new token, we use the cached key and value of previous tokens instead of recomputing every thing from scratch. Therefore, to estimate the context of a brand new token, the eye of earlier tokens needs to be recalculated. The layer will then use these values to estimate the context of this explicit token with respect to the earlier tokens, a process generally known as the attention mechanism.
However, the way in which the eye mechanism is calculated poses a big disadvantage. DeepSeek V3 additionally makes use of KV cache in its attention layer. KV Cache administration in vLLM. As the identify suggests, with KV cache, the key and value of a new token are saved in a cache during every technology course of. This effectively quickens the token era course of. On account of this compression, the scale of key, value, and question vectors turns into even smaller, thereby optimizing the reminiscence for KV cache and speeding up the token era course of. This leads to a really gradual token technology process throughout inference. The RoPE method is necessary for introducing positional info of the new token in a sequence. Once compressed, the low-rank representation of the query vector is then processed by two totally different pipelines: one is projected directly with a layer to map it back into its high-dimensional illustration, and one other is processed by an approach called Rotary Positional Embedding (RoPE). However, the enter for RoPE of the important thing vector comes from the original enter embedding as an alternative of the compressed key-worth vector. This community has two major obligations: to analyze the input question and then route it to the most applicable knowledgeable models.
If you have any concerns relating to where and exactly how to make use of شات DeepSeek, you could contact us at our own page.
- 이전글Fighting For Deepseek Ai News: The Samurai Way 25.02.09
- 다음글рабочая ссылка на кракен 25.02.09
댓글목록
등록된 댓글이 없습니다.