
Ho To (Do) Deepseek Ai With out Leaving Your Office(House).
페이지 정보

본문
China’s AI firms have made a protracted approach to rise, and they nonetheless are an extended approach to flourish. For every perform extracted, we then ask an LLM to supply a written summary of the perform and use a second LLM to put in writing a function matching this abstract, in the identical manner as earlier than. ""BALROG is tough to solve by way of easy memorization - all of the environments used within the benchmark are procedurally generated, and encountering the identical occasion of an surroundings twice is unlikely," they write. For now, the prices are far larger, as they involve a mix of extending open-supply tools just like the OLMo code and poaching expensive staff that can re-solve problems at the frontier of AI. For instance, in case you have a chunk of code with one thing lacking in the middle, the mannequin can predict what must be there primarily based on the surrounding code. We've got explored DeepSeek’s strategy to the development of superior fashions. When you have any strong information on the topic I would love to listen to from you in non-public, do some little bit of investigative journalism, and write up a real article or video on the matter. An actual surprise, he says, is how much more effectively and cheaply the DeepSeek AI was skilled.
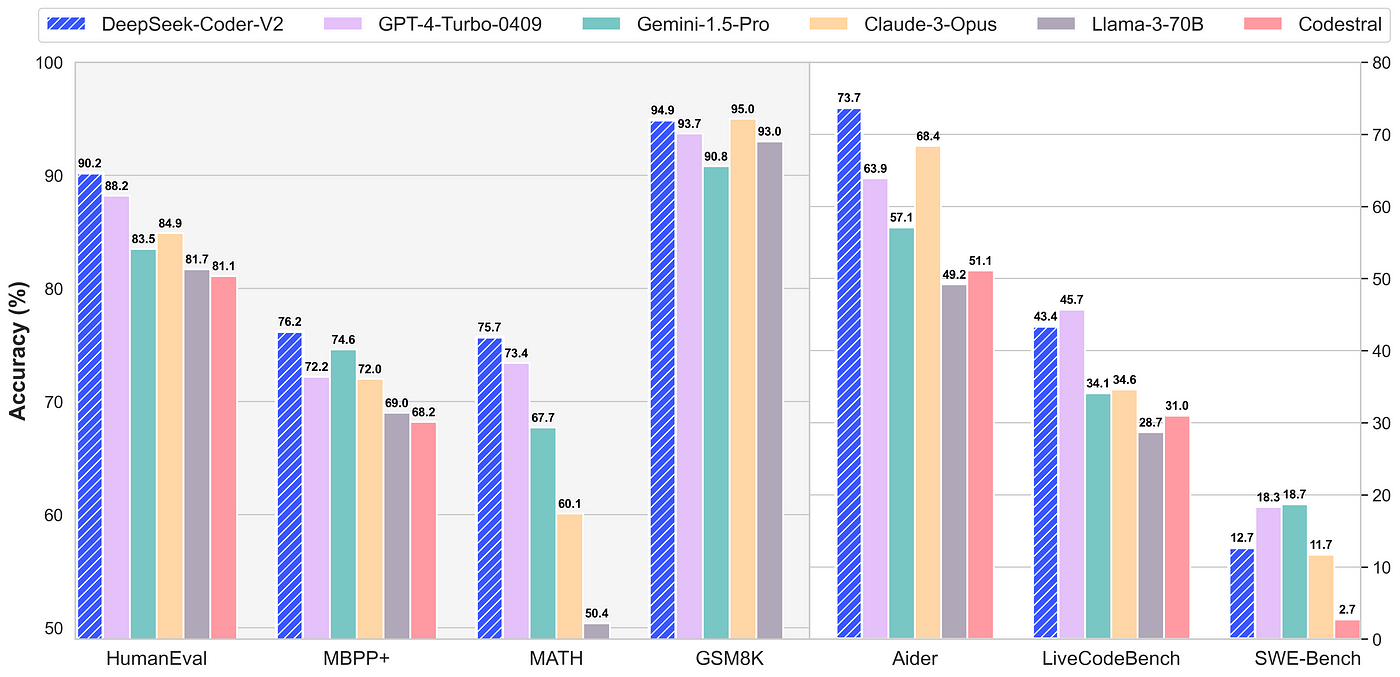 Handling long contexts: DeepSeek-Coder-V2 extends the context size from 16,000 to 128,000 tokens, permitting it to work with much larger and more complicated tasks. Training data: Compared to the unique DeepSeek-Coder, DeepSeek-Coder-V2 expanded the coaching data considerably by including an extra 6 trillion tokens, growing the whole to 10.2 trillion tokens. You use the same approach as when coaching your mannequin: for decoder transformers, you teach your model to foretell the next words one by one (referred to as an auto-regressive strategy). By having shared specialists, the mannequin doesn't must retailer the same data in a number of locations. This enables the model to process info sooner and with less memory without dropping accuracy. Risk of dropping info whereas compressing information in MLA. Cyber researchers who set out to probe DeepSeek’s safety stated they found a publicly accessible database belonging to the company that contained internal information. Partsol, a Tampa software company formerly often called Partnership Solutions International, aims to leverage its Cognitive AI know-how - software that tries to suppose and learn by imitating how human brains work.
Handling long contexts: DeepSeek-Coder-V2 extends the context size from 16,000 to 128,000 tokens, permitting it to work with much larger and more complicated tasks. Training data: Compared to the unique DeepSeek-Coder, DeepSeek-Coder-V2 expanded the coaching data considerably by including an extra 6 trillion tokens, growing the whole to 10.2 trillion tokens. You use the same approach as when coaching your mannequin: for decoder transformers, you teach your model to foretell the next words one by one (referred to as an auto-regressive strategy). By having shared specialists, the mannequin doesn't must retailer the same data in a number of locations. This enables the model to process info sooner and with less memory without dropping accuracy. Risk of dropping info whereas compressing information in MLA. Cyber researchers who set out to probe DeepSeek’s safety stated they found a publicly accessible database belonging to the company that contained internal information. Partsol, a Tampa software company formerly often called Partnership Solutions International, aims to leverage its Cognitive AI know-how - software that tries to suppose and learn by imitating how human brains work.
Chinese artificial intelligence company DeepSeek disrupted Silicon Valley with the discharge of cheaply developed AI models that compete with flagship offerings from OpenAI - but the ChatGPT maker suspects they had been built upon OpenAI knowledge. The researchers used an iterative course of to generate artificial proof knowledge. Mixture-of-Experts (MoE): Instead of utilizing all 236 billion parameters for every activity, DeepSeek-V2 solely activates a portion (21 billion) primarily based on what it needs to do. Before we might begin using Binoculars, we wanted to create a sizeable dataset of human and AI-written code, that contained samples of varied tokens lengths. It’s trained on 60% supply code, 10% math corpus, and 30% pure language. LLaMA (Large Language Model Meta AI) is Meta’s (Facebook) suite of giant-scale language models. Model Cards: Introduced in a Google research paper, these paperwork present transparency about an AI model's meant use, limitations, and efficiency metrics throughout totally different demographics. In general, the scoring for the write-checks eval activity consists of metrics that assess the standard of the response itself (e.g. Does the response contain code?, Does the response include chatter that is not code?), the quality of code (e.g. Does the code compile?, Is the code compact?), and the standard of the execution outcomes of the code.
For the previous eval model it was enough to examine if the implementation was coated when executing a check (10 factors) or not (0 points). Model dimension and architecture: The DeepSeek-Coder-V2 model is available in two fundamental sizes: a smaller version with sixteen B parameters and a larger one with 236 B parameters. That means the model can’t be trusted to self-establish, for one. A short essay about one of the ‘societal safety’ problems that highly effective AI implies. What issues does it resolve? Sophisticated architecture with Transformers, MoE and MLA. 두 모델 모두 DeepSeekMoE에서 시도했던, DeepSeek만의 업그레이드된 MoE 방식을 기반으로 구축되었는데요. 먼저 기본적인 MoE (Mixture of Experts) 아키텍처를 생각해 보죠. This reduces redundancy, making certain that other experts give attention to distinctive, specialised areas. In actual fact experts additionally consider a thriving open-supply culture has allowed younger begin-ups to pool resources and advance sooner. This makes it more efficient because it does not waste resources on unnecessary computations. 0150 - Local AI has more insights. Unlike more acquainted chatbots like ChatGPT, Gemini, and Perplexity, that will provide detailed responses on a variety of topics, together with politically sensitive ones, DeepSeek's chatbot aligns its responses with official Chinese narratives. Users who register or log in to DeepSeek could unknowingly be creating accounts in China, making their identities, search queries, and online habits seen to Chinese state systems.
In the event you beloved this post in addition to you wish to acquire more information relating to ديب سيك شات kindly stop by our own webpage.
- 이전글The Biggest Problem in Deepseek Comes All the Way down to This Word That Starts With "W" 25.02.09
- 다음글مو مجرد تنظيف عادي! 25.02.09
댓글목록
등록된 댓글이 없습니다.