
In Contrast to Plain Buffered I/O
페이지 정보

본문
DeepSeek Coder V2 represents a major leap forward within the realm of AI-powered coding and mathematical reasoning. Our pipeline elegantly incorporates the verification and reflection patterns of R1 into DeepSeek-V3 and notably improves its reasoning performance. As for the coaching framework, we design the DualPipe algorithm for efficient pipeline parallelism, which has fewer pipeline bubbles and hides most of the communication during training by computation-communication overlap. HaiScale Distributed Data Parallel (DDP): Parallel training library that implements varied types of parallelism akin to Data Parallelism (DP), Pipeline Parallelism (PP), Tensor Parallelism (TP), Experts Parallelism (EP), Fully Sharded Data Parallel (FSDP) and Zero Redundancy Optimizer (ZeRO). This overlap ensures that, as the mannequin additional scales up, so long as we maintain a relentless computation-to-communication ratio, we are able to nonetheless make use of wonderful-grained consultants across nodes whereas achieving a near-zero all-to-all communication overhead. Specifically, throughout the expectation step, the "burden" for explaining each data level is assigned over the experts, and throughout the maximization step, the specialists are educated to improve the explanations they bought a excessive burden for, while the gate is educated to enhance its burden assignment.
 With its MIT license and clear pricing structure, DeepSeek-R1 empowers users to innovate freely whereas preserving prices under control. Lastly, we emphasize once more the economical coaching prices of DeepSeek-V3, summarized in Table 1, achieved by way of our optimized co-design of algorithms, frameworks, and hardware. This considerably enhances our training efficiency and reduces the coaching costs, enabling us to additional scale up the mannequin dimension without additional overhead. For MoE fashions, an unbalanced expert load will lead to routing collapse (Shazeer et al., 2017) and diminish computational efficiency in situations with professional parallelism. Combining these efforts, we achieve excessive coaching efficiency. Throughout the entire training course of, we didn't encounter any irrecoverable loss spikes or have to roll again. The CopilotKit lets you employ GPT fashions to automate interplay along with your utility's front and back end. On 29 November 2023, DeepSeek released the DeepSeek - LLM series of fashions. It seems designed with a collection of nicely-intentioned actors in mind: the freelance photojournalist using the right cameras and the correct enhancing software program, providing pictures to a prestigious newspaper that may take some time to indicate C2PA metadata in its reporting. Its chat model also outperforms different open-source models and achieves efficiency comparable to leading closed-supply fashions, including GPT-4o and Claude-3.5-Sonnet, on a series of normal and open-ended benchmarks.
With its MIT license and clear pricing structure, DeepSeek-R1 empowers users to innovate freely whereas preserving prices under control. Lastly, we emphasize once more the economical coaching prices of DeepSeek-V3, summarized in Table 1, achieved by way of our optimized co-design of algorithms, frameworks, and hardware. This considerably enhances our training efficiency and reduces the coaching costs, enabling us to additional scale up the mannequin dimension without additional overhead. For MoE fashions, an unbalanced expert load will lead to routing collapse (Shazeer et al., 2017) and diminish computational efficiency in situations with professional parallelism. Combining these efforts, we achieve excessive coaching efficiency. Throughout the entire training course of, we didn't encounter any irrecoverable loss spikes or have to roll again. The CopilotKit lets you employ GPT fashions to automate interplay along with your utility's front and back end. On 29 November 2023, DeepSeek released the DeepSeek - LLM series of fashions. It seems designed with a collection of nicely-intentioned actors in mind: the freelance photojournalist using the right cameras and the correct enhancing software program, providing pictures to a prestigious newspaper that may take some time to indicate C2PA metadata in its reporting. Its chat model also outperforms different open-source models and achieves efficiency comparable to leading closed-supply fashions, including GPT-4o and Claude-3.5-Sonnet, on a series of normal and open-ended benchmarks.
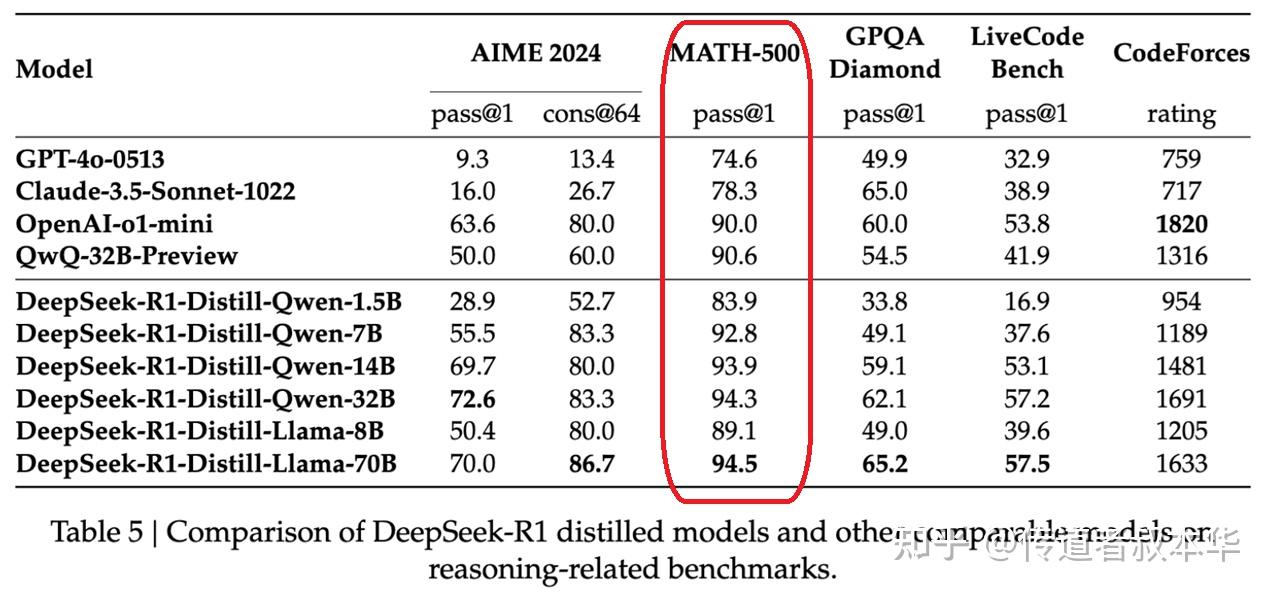
The mannequin's efficiency in mathematical reasoning is especially impressive. TLDR excessive-high quality reasoning models are getting significantly cheaper and more open-source. This could change the AI development and competition landscape and enterprise models. For many who choose a extra interactive expertise, DeepSeek offers an internet-primarily based chat interface the place you can interact with DeepSeek Coder V2 immediately. They're people who were previously at massive firms and felt like the corporate couldn't transfer themselves in a means that goes to be on monitor with the brand new know-how wave. Who leaves versus who joins? During the pre-training stage, coaching DeepSeek-V3 on every trillion tokens requires only 180K H800 GPU hours, i.e., 3.7 days on our cluster with 2048 H800 GPUs. During pre-training, we practice DeepSeek-V3 on 14.8T high-quality and various tokens. • At an economical cost of only 2.664M H800 GPU hours, we complete the pre-coaching of DeepSeek-V3 on 14.8T tokens, producing the at present strongest open-supply base mannequin. The pre-coaching process is remarkably stable.
Despite its economical coaching prices, comprehensive evaluations reveal that DeepSeek-V3-Base has emerged as the strongest open-source base mannequin at present obtainable, particularly in code and math. While much attention within the AI neighborhood has been focused on models like LLaMA and Mistral, DeepSeek has emerged as a major participant that deserves closer examination. For comparability, the equal open-supply Llama 3 405B mannequin requires 30.8 million GPU hours for training. POSTSUBSCRIPT. During coaching, we keep monitoring the expert load on the whole batch of each training step. But it certain makes me surprise simply how a lot money Vercel has been pumping into the React team, what number of members of that group it stole and the way that affected the React docs and the team itself, both immediately or by "my colleague used to work here and now's at Vercel they usually keep telling me Next is great". While U.S. companies have been barred from promoting delicate applied sciences directly to China beneath Department of Commerce export controls, U.S. "It is in the U.S. DeepSeek AI Coder V2 demonstrates outstanding proficiency in each mathematical reasoning and coding duties, setting new benchmarks in these domains. These benchmark outcomes spotlight DeepSeek Coder V2's aggressive edge in each coding and mathematical reasoning duties.
Should you liked this short article in addition to you desire to acquire details concerning شات ديب سيك kindly go to our web page.
- 이전글sal de mesa 25.02.08
- 다음글Is Tech Making Robot Vacuum Better Or Worse? 25.02.08
댓글목록
등록된 댓글이 없습니다.