
Is Taiwan a Rustic?
페이지 정보

본문
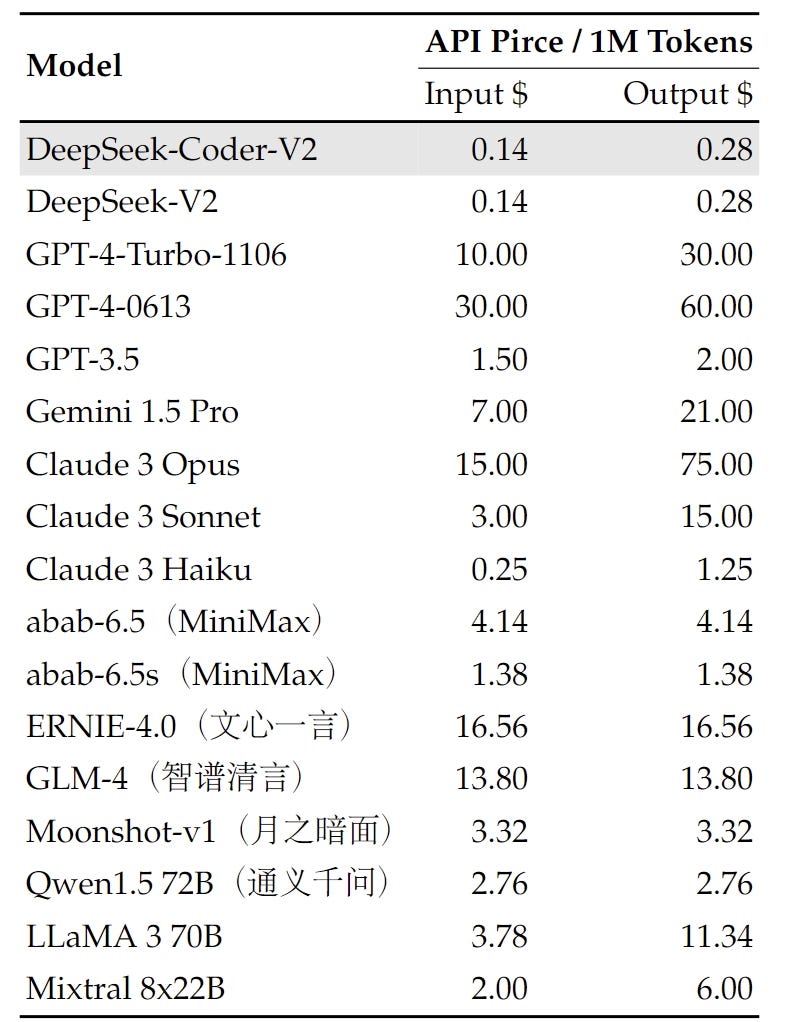 DeepSeek consistently adheres to the route of open-source fashions with longtermism, aiming to steadily approach the last word objective of AGI (Artificial General Intelligence). FP8-LM: Training FP8 large language fashions. Better & sooner massive language models through multi-token prediction. In addition to the MLA and DeepSeekMoE architectures, it additionally pioneers an auxiliary-loss-free strategy for load balancing and units a multi-token prediction coaching objective for stronger performance. On C-Eval, a representative benchmark for Chinese educational information evaluation, and CLUEWSC (Chinese Winograd Schema Challenge), DeepSeek-V3 and Qwen2.5-72B exhibit similar efficiency levels, indicating that both fashions are nicely-optimized for difficult Chinese-language reasoning and educational tasks. For the DeepSeek-V2 model series, we choose essentially the most representative variants for comparison. This resulted in DeepSeek-V2. Compared with DeepSeek 67B, DeepSeek-V2 achieves stronger performance, and in the meantime saves 42.5% of coaching costs, reduces the KV cache by 93.3%, and boosts the utmost technology throughput to 5.76 occasions. As well as, on GPQA-Diamond, a PhD-degree evaluation testbed, DeepSeek-V3 achieves outstanding results, rating just behind Claude 3.5 Sonnet and outperforming all different competitors by a considerable margin. DeepSeek-V3 demonstrates competitive efficiency, standing on par with top-tier models resembling LLaMA-3.1-405B, GPT-4o, and Claude-Sonnet 3.5, while considerably outperforming Qwen2.5 72B. Moreover, DeepSeek-V3 excels in MMLU-Pro, a extra challenging academic data benchmark, the place it intently trails Claude-Sonnet 3.5. On MMLU-Redux, a refined version of MMLU with corrected labels, DeepSeek-V3 surpasses its friends.
DeepSeek consistently adheres to the route of open-source fashions with longtermism, aiming to steadily approach the last word objective of AGI (Artificial General Intelligence). FP8-LM: Training FP8 large language fashions. Better & sooner massive language models through multi-token prediction. In addition to the MLA and DeepSeekMoE architectures, it additionally pioneers an auxiliary-loss-free strategy for load balancing and units a multi-token prediction coaching objective for stronger performance. On C-Eval, a representative benchmark for Chinese educational information evaluation, and CLUEWSC (Chinese Winograd Schema Challenge), DeepSeek-V3 and Qwen2.5-72B exhibit similar efficiency levels, indicating that both fashions are nicely-optimized for difficult Chinese-language reasoning and educational tasks. For the DeepSeek-V2 model series, we choose essentially the most representative variants for comparison. This resulted in DeepSeek-V2. Compared with DeepSeek 67B, DeepSeek-V2 achieves stronger performance, and in the meantime saves 42.5% of coaching costs, reduces the KV cache by 93.3%, and boosts the utmost technology throughput to 5.76 occasions. As well as, on GPQA-Diamond, a PhD-degree evaluation testbed, DeepSeek-V3 achieves outstanding results, rating just behind Claude 3.5 Sonnet and outperforming all different competitors by a considerable margin. DeepSeek-V3 demonstrates competitive efficiency, standing on par with top-tier models resembling LLaMA-3.1-405B, GPT-4o, and Claude-Sonnet 3.5, while considerably outperforming Qwen2.5 72B. Moreover, DeepSeek-V3 excels in MMLU-Pro, a extra challenging academic data benchmark, the place it intently trails Claude-Sonnet 3.5. On MMLU-Redux, a refined version of MMLU with corrected labels, DeepSeek-V3 surpasses its friends.
Are we done with mmlu? After all we're performing some anthropomorphizing however the intuition right here is as well based as anything else. For closed-supply models, evaluations are performed by their respective APIs. The series contains 4 models, 2 base fashions (DeepSeek-V2, deepseek ai-V2-Lite) and a pair of chatbots (-Chat). The fashions are available on GitHub and Hugging Face, together with the code and data used for training and analysis. The reward for code problems was generated by a reward model skilled to foretell whether a program would cross the unit assessments. The baseline is skilled on brief CoT information, whereas its competitor uses information generated by the knowledgeable checkpoints described above. CoT and test time compute have been proven to be the long run route of language fashions for better or for worse. Our analysis means that information distillation from reasoning models presents a promising direction for post-training optimization. Table 8 presents the efficiency of those fashions in RewardBench (Lambert et al., 2024). DeepSeek-V3 achieves efficiency on par with the perfect versions of GPT-4o-0806 and Claude-3.5-Sonnet-1022, whereas surpassing other variations. During the development of DeepSeek-V3, for these broader contexts, we employ the constitutional AI approach (Bai et al., 2022), leveraging the voting analysis outcomes of DeepSeek-V3 itself as a feedback source.
Therefore, we employ DeepSeek-V3 together with voting to supply self-feedback on open-ended questions, thereby bettering the effectiveness and robustness of the alignment course of. Table 9 demonstrates the effectiveness of the distillation knowledge, exhibiting important improvements in each LiveCodeBench and MATH-500 benchmarks. We ablate the contribution of distillation from DeepSeek-R1 primarily based on DeepSeek-V2.5. All models are evaluated in a configuration that limits the output size to 8K. Benchmarks containing fewer than one thousand samples are tested a number of occasions utilizing various temperature settings to derive strong ultimate results. To reinforce its reliability, we construct preference information that not only offers the final reward but in addition consists of the chain-of-thought resulting in the reward. For questions with free-type floor-truth answers, we depend on the reward mannequin to determine whether or not the response matches the anticipated floor-fact. This reward model was then used to train Instruct utilizing group relative policy optimization (GRPO) on a dataset of 144K math questions "associated to GSM8K and MATH". Unsurprisingly, DeepSeek didn't provide solutions to questions on certain political occasions. By 27 January 2025 the app had surpassed ChatGPT as the highest-rated free app on the iOS App Store within the United States; its chatbot reportedly solutions questions, solves logic problems and writes computer applications on par with other chatbots available on the market, in response to benchmark tests used by American A.I.
Its interface is intuitive and it provides answers instantaneously, except for occasional outages, which it attributes to high visitors. This excessive acceptance price enables DeepSeek-V3 to attain a considerably improved decoding speed, delivering 1.Eight instances TPS (Tokens Per Second). On the small scale, we prepare a baseline MoE mannequin comprising roughly 16B total parameters on 1.33T tokens. On 29 November 2023, deepseek ai china released the DeepSeek-LLM collection of fashions, with 7B and 67B parameters in each Base and Chat kinds (no Instruct was released). We compare the judgment ability of DeepSeek-V3 with state-of-the-artwork models, ديب سيك namely GPT-4o and Claude-3.5. The reward model is skilled from the DeepSeek-V3 SFT checkpoints. This method helps mitigate the risk of reward hacking in specific tasks. This stage used 1 reward model, educated on compiler suggestions (for coding) and floor-reality labels (for math). In domains the place verification through external instruments is simple, similar to some coding or arithmetic situations, RL demonstrates exceptional efficacy.
If you cherished this article and you would like to obtain more info about ديب سيك kindly visit our own webpage.
- 이전글Deepseek For Cash 25.02.01
- 다음글Ever Heard About Extreme Deepseek? Well About That... 25.02.01
댓글목록
등록된 댓글이 없습니다.