
Free Deepseek Ai Coaching Servies
페이지 정보

본문
 Nvidia inventory fell 3.58% to a low of $141.88 in the earlier session on Nasdaq towards a close of $147.15 on January 24. Later, the stock closed 3.12% lower at $142.62. DeepSeek AI's launch comes hot on the heels of the announcement of the most important non-public funding in AI infrastructure ever: Project Stargate, announced January 21, is a $500 billion funding by OpenAI, Oracle, SoftBank, and MGX, who will associate with companies like Microsoft and NVIDIA to construct out AI-targeted services within the US. Kimery, Anthony (26 January 2025). "China's DeepSeek AI poses formidable cyber, information privacy threats". ChatGPT maker OpenAI. The mannequin was additionally extra value-effective, utilizing expensive Nvidia chips to prepare the system on troves of data. Unlike traditional fashions that rely heavily on supervised studying with intensive labeled datasets, DeepSeek-R1 was developed utilizing a reinforcement studying (RL)-first approach. DeepSeek's latest model, DeepSeek-V3, builds upon the inspiration laid by its predecessor, DeepSeek-R1. Early estimates recommend that rolling out ChatGPT’s newest language model, GPT4, demanded colossal GPU capability for weeks on end. MrT5: Dynamic Token Merging for Efficient Byte-level Language Models. It's unclear whether DeepSeek’s strategy will assist to make models with better performance overall, or just models which can be extra efficient.
Nvidia inventory fell 3.58% to a low of $141.88 in the earlier session on Nasdaq towards a close of $147.15 on January 24. Later, the stock closed 3.12% lower at $142.62. DeepSeek AI's launch comes hot on the heels of the announcement of the most important non-public funding in AI infrastructure ever: Project Stargate, announced January 21, is a $500 billion funding by OpenAI, Oracle, SoftBank, and MGX, who will associate with companies like Microsoft and NVIDIA to construct out AI-targeted services within the US. Kimery, Anthony (26 January 2025). "China's DeepSeek AI poses formidable cyber, information privacy threats". ChatGPT maker OpenAI. The mannequin was additionally extra value-effective, utilizing expensive Nvidia chips to prepare the system on troves of data. Unlike traditional fashions that rely heavily on supervised studying with intensive labeled datasets, DeepSeek-R1 was developed utilizing a reinforcement studying (RL)-first approach. DeepSeek's latest model, DeepSeek-V3, builds upon the inspiration laid by its predecessor, DeepSeek-R1. Early estimates recommend that rolling out ChatGPT’s newest language model, GPT4, demanded colossal GPU capability for weeks on end. MrT5: Dynamic Token Merging for Efficient Byte-level Language Models. It's unclear whether DeepSeek’s strategy will assist to make models with better performance overall, or just models which can be extra efficient.
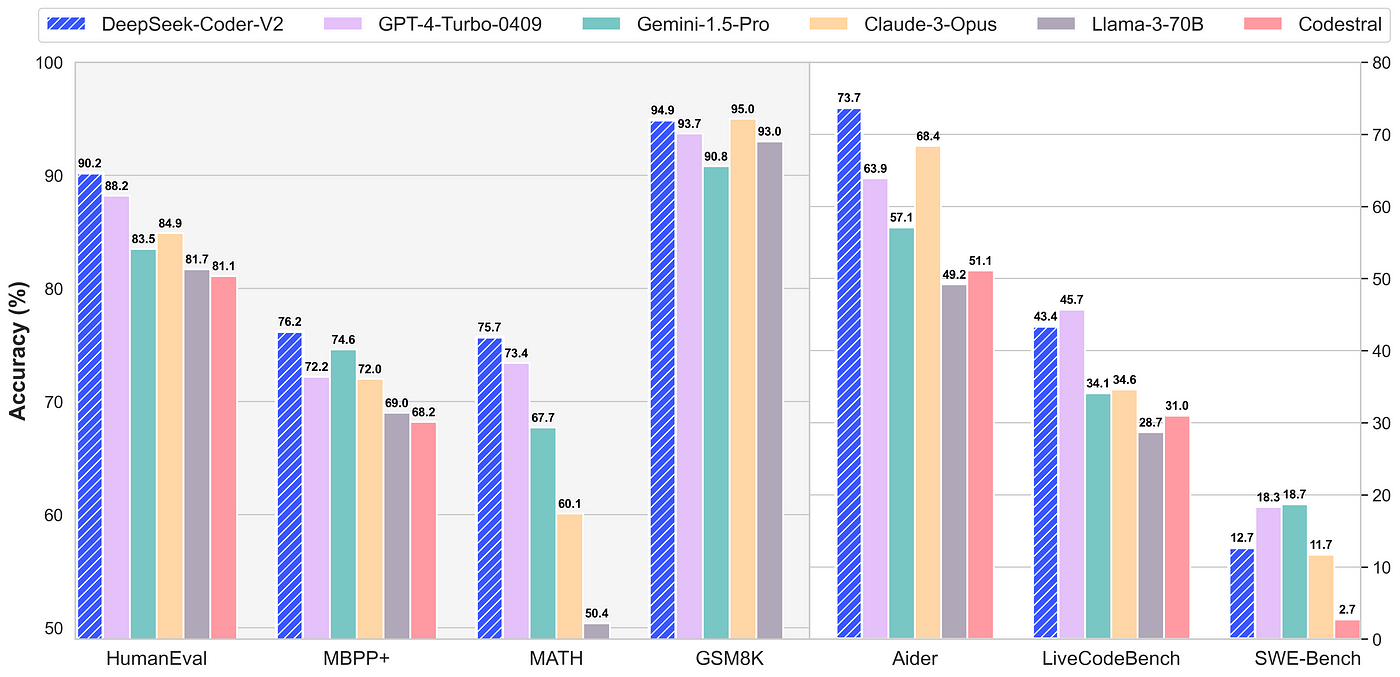 Will it scale back the variety of human programming gigs? This process rewards the model for producing outputs that align with human preferences and penalizes it for undesirable outputs. The DeepSeek R1 reasoner model not solely matches the performance of leading fashions like OpenAI's o1 but does so with exceptional cost effectivity. It uses a hybrid structure and a "chain of thought" reasoning technique to break down complex problems step-by-step-similar to how GPT fashions operate but with a deal with higher effectivity. The mannequin employs a Mixture-of-Experts (MoE) architecture (explained later), which activates 37 billion parameters out of 671 billion. Mixture-of-Experts (MoE) Architecture: DeepSeek-V3 employs a Mixture-of-Experts framework composed of a number of specialised neural networks, every optimized for particular duties. DeepSeek claims it has considerably diminished the compute and reminiscence calls for sometimes required for models of this scale utilizing superior pipeline algorithms, optimized communication framework, and FP8 low-precision computation in addition to communication. Reinforcement studying: The model is then nice-tuned using reinforcement studying algorithms. These algorithms interpret the question-not just the phrases but additionally the context and meaning. All of the massive LLMs will behave this way, striving to provide all the context that a consumer is searching for straight on their very own platforms, such that the platform supplier can continue to seize your knowledge (prompt query history) and to inject into types of commerce where doable (advertising, purchasing, and many others).
Will it scale back the variety of human programming gigs? This process rewards the model for producing outputs that align with human preferences and penalizes it for undesirable outputs. The DeepSeek R1 reasoner model not solely matches the performance of leading fashions like OpenAI's o1 but does so with exceptional cost effectivity. It uses a hybrid structure and a "chain of thought" reasoning technique to break down complex problems step-by-step-similar to how GPT fashions operate but with a deal with higher effectivity. The mannequin employs a Mixture-of-Experts (MoE) architecture (explained later), which activates 37 billion parameters out of 671 billion. Mixture-of-Experts (MoE) Architecture: DeepSeek-V3 employs a Mixture-of-Experts framework composed of a number of specialised neural networks, every optimized for particular duties. DeepSeek claims it has considerably diminished the compute and reminiscence calls for sometimes required for models of this scale utilizing superior pipeline algorithms, optimized communication framework, and FP8 low-precision computation in addition to communication. Reinforcement studying: The model is then nice-tuned using reinforcement studying algorithms. These algorithms interpret the question-not just the phrases but additionally the context and meaning. All of the massive LLMs will behave this way, striving to provide all the context that a consumer is searching for straight on their very own platforms, such that the platform supplier can continue to seize your knowledge (prompt query history) and to inject into types of commerce where doable (advertising, purchasing, and many others).
2023-09-11 CodeFuse-CodeLlama34B has achived 74.4% of pass@1 (greedy decoding) on HumanEval, which is SOTA results for open-sourced LLMs at current. The DeepSeek-Coder-Instruct-33B mannequin after instruction tuning outperforms GPT35-turbo on HumanEval and achieves comparable outcomes with GPT35-turbo on MBPP. DeepSeek was founded in December 2023 by Liang Wenfeng, and released its first AI giant language mannequin the next 12 months. DeepSeek: Trained on a large dataset of Chinese textual content and code, with a focus on Chinese language and culture. This capability accelerates the inference course of and improves the model’s capability to generate coherent, contextually related textual content. The training course of blends pure reinforcement learning (DeepSeek-R1-Zero) with initial knowledge and iterative tremendous-tuning. This iterative course of allows R1 to be taught and refine its skills primarily based on human feedback, leading to notable improvements in its reasoning and downside-solving abilities. Some experts dismiss these notions and consider that such extraordinary capabilities are far off or, even if they arrived, would not lead to loss of human management over AI techniques.
Human feedback: Human experts provide suggestions on the model's outputs, guiding it towards extra correct and useful responses. The findings of this research counsel that, by way of a mixture of targeted alignment coaching and keyword filtering, it is possible to tailor the responses of LLM chatbots to mirror the values endorsed by Beijing. The people research this as effectively and should not have words for it - they merely checklist these as examples of me getting distracted. "Just put the animal in the atmosphere and see what it does" is the definition of a qualitative examine and by nature one thing where it’s onerous to ablate and management issues to do really honest comparisons. It’s not broadly understood now as a result of society as a complete needs to study from reality. Experimentation and development could now be considerably simpler for us. Others, including Meta and OpenAI, are reconsidering their technical prowess in AI software program growth. OpenAI, which is only actually open about consuming all the world's vitality and half a trillion of our taxpayer dollars, just bought rattled to its core. Reportedly, it had entry to about 50,000 of Nvidia’s H100 AI GPUs, that are from the last era of advanced AI chips.
- 이전글Why My Deepseek Ai Is Better Than Yours 25.02.04
- 다음글What Ancient Greeks Knew About Deepseek Ai That You still Don't 25.02.04
댓글목록
등록된 댓글이 없습니다.