
Believe In Your Deepseek Chatgpt Skills But Never Stop Improving
페이지 정보

본문
 ARG affinity scores of the experts distributed on each node. ARG times. Although DualPipe requires preserving two copies of the model parameters, this does not significantly improve the memory consumption since we use a large EP dimension throughout training. The US begin-up has been taking a closed-supply method, keeping data reminiscent of the particular coaching strategies and vitality costs of its fashions tightly guarded. Just like the device-restricted routing utilized by DeepSeek-V2, DeepSeek-V3 additionally uses a restricted routing mechanism to restrict communication prices during coaching. Slightly different from DeepSeek-V2, DeepSeek-V3 uses the sigmoid operate to compute the affinity scores, and applies a normalization amongst all chosen affinity scores to supply the gating values. We completed a spread of research tasks to research how elements like programming language, the variety of tokens within the input, models used calculate the rating and the models used to produce our AI-written code, would affect the Binoculars scores and ultimately, how effectively Binoculars was ready to tell apart between human and AI-written code. Limitations: May be slower for easy tasks and requires extra computational energy. We'll post more updates when we have them.
ARG affinity scores of the experts distributed on each node. ARG times. Although DualPipe requires preserving two copies of the model parameters, this does not significantly improve the memory consumption since we use a large EP dimension throughout training. The US begin-up has been taking a closed-supply method, keeping data reminiscent of the particular coaching strategies and vitality costs of its fashions tightly guarded. Just like the device-restricted routing utilized by DeepSeek-V2, DeepSeek-V3 additionally uses a restricted routing mechanism to restrict communication prices during coaching. Slightly different from DeepSeek-V2, DeepSeek-V3 uses the sigmoid operate to compute the affinity scores, and applies a normalization amongst all chosen affinity scores to supply the gating values. We completed a spread of research tasks to research how elements like programming language, the variety of tokens within the input, models used calculate the rating and the models used to produce our AI-written code, would affect the Binoculars scores and ultimately, how effectively Binoculars was ready to tell apart between human and AI-written code. Limitations: May be slower for easy tasks and requires extra computational energy. We'll post more updates when we have them.
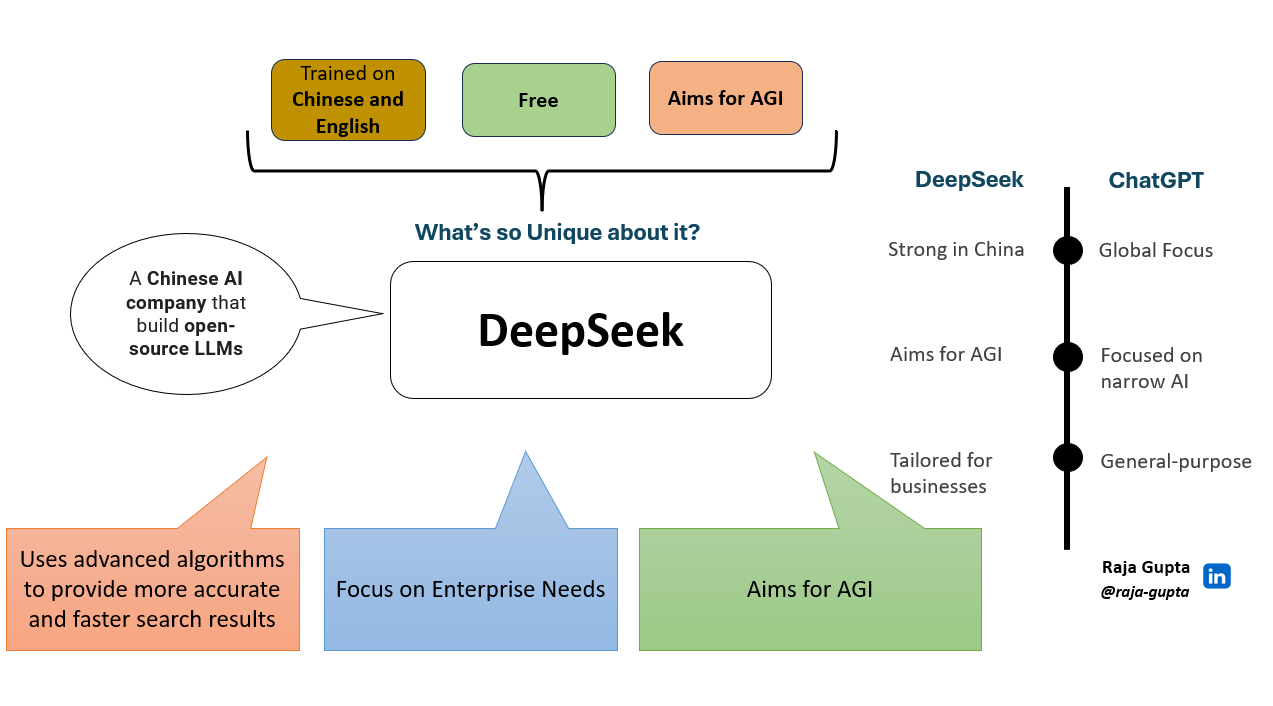
 I've played a number of other video games with DeepSeek-R1. The model, dubbed R1, came out on Jan. 20, just a few months after DeepSeek launched its first model. Chinese AI startup MiniMax launched several open-source models with the hope that "there will be encouragement for good work and criticism for dangerous work, and other people outside will be capable to contribute." Chinese analysts pointed out that cost-effective open-supply fashions assist widespread entry and adoption, together with to nations in the global South. Chinese startup DeepSeek has constructed and launched DeepSeek-V2, a surprisingly highly effective language mannequin. So, is DeepSeek the AI assistant you’ve been waiting for? Export legal guidelines restricted the available assets so, Chinese engineers needed to get creative and they did. On 10 January 2025, DeepSeek, a Chinese AI company that develops generative AI fashions, launched a free ‘AI Assistant’ app for iPhone and Android. Trump argued that America has "the best scientists on this planet" residing in tech bubbles like Silicon Valley and Seattle, an American firm should have created a generative AI that is quicker and reasonably priced.
I've played a number of other video games with DeepSeek-R1. The model, dubbed R1, came out on Jan. 20, just a few months after DeepSeek launched its first model. Chinese AI startup MiniMax launched several open-source models with the hope that "there will be encouragement for good work and criticism for dangerous work, and other people outside will be capable to contribute." Chinese analysts pointed out that cost-effective open-supply fashions assist widespread entry and adoption, together with to nations in the global South. Chinese startup DeepSeek has constructed and launched DeepSeek-V2, a surprisingly highly effective language mannequin. So, is DeepSeek the AI assistant you’ve been waiting for? Export legal guidelines restricted the available assets so, Chinese engineers needed to get creative and they did. On 10 January 2025, DeepSeek, a Chinese AI company that develops generative AI fashions, launched a free ‘AI Assistant’ app for iPhone and Android. Trump argued that America has "the best scientists on this planet" residing in tech bubbles like Silicon Valley and Seattle, an American firm should have created a generative AI that is quicker and reasonably priced.
That makes it the most beneficial company on the planet, overtaking Microsoft’s heady $3.32 trillion market cap. This overlap also ensures that, because the model further scales up, as long as we maintain a continuing computation-to-communication ratio, we will still make use of fine-grained consultants throughout nodes whereas achieving a close to-zero all-to-all communication overhead. For DeepSeek-V3, the communication overhead launched by cross-node professional parallelism results in an inefficient computation-to-communication ratio of approximately 1:1. To tackle this problem, we design an revolutionary pipeline parallelism algorithm referred to as DualPipe, which not only accelerates mannequin training by effectively overlapping forward and backward computation-communication phases, but additionally reduces the pipeline bubbles. Under this constraint, our MoE coaching framework can almost obtain full computation-communication overlap. The fundamental structure of DeepSeek-V3 remains to be within the Transformer (Vaswani et al., 2017) framework. The coaching of DeepSeek-V3 is supported by the HAI-LLM framework, an efficient and lightweight training framework crafted by our engineers from the ground up. Our precept of sustaining the causal chain of predictions is much like that of EAGLE (Li et al., 2024b), but its primary objective is speculative decoding (Xia et al., 2023; Leviathan et al., 2023), whereas we make the most of MTP to enhance training.
Then, we current a Multi-Token Prediction (MTP) training objective, which we now have noticed to boost the general efficiency on analysis benchmarks. Through the dynamic adjustment, DeepSeek-V3 retains balanced expert load throughout training, and achieves better performance than fashions that encourage load stability by pure auxiliary losses. However, too giant an auxiliary loss will impair the mannequin efficiency (Wang et al., 2024a). To achieve a greater trade-off between load stability and model performance, we pioneer an auxiliary-loss-free load balancing technique (Wang et al., 2024a) to make sure load stability. Compared with DeepSeek Chat-V2, an exception is that we additionally introduce an auxiliary-loss-Free DeepSeek load balancing strategy (Wang et al., 2024a) for DeepSeekMoE to mitigate the performance degradation induced by the trouble to ensure load steadiness. Our MTP strategy mainly aims to improve the efficiency of the principle model, so during inference, we can instantly discard the MTP modules and the principle mannequin can perform independently and normally.
- 이전글Best Online Casinos In the US 25.02.28
- 다음글The Interesting State Of Hip Hop In The South 25.02.28
댓글목록
등록된 댓글이 없습니다.