
The Basic Of Deepseek
페이지 정보

본문
 That said, you can entry uncensored, US-primarily based variations of DeepSeek by way of platforms like Perplexity. Cloud Platform Access : If deploying on AWS, GCP, or Azure, having an energetic account on any of those platforms will assist with palms-on learning. You will learn to deploy, manage, and optimize these powerful models across various cloud platforms, including AWS, GCP, and Azure. Humans, including high gamers, want a number of practice and training to become good at chess. On January 27, 2025, major tech corporations, together with Microsoft, Meta, Nvidia, and Alphabet, collectively lost over $1 trillion in market value. This article explores the true-world purposes of DeepSeek’s technologies whereas clarifying misconceptions concerning the DEEPSEEKAI token that exists within the crypto market however is unaffiliated with the corporate. DeepSeek was founded lower than 2 years ago, has 200 employees, and was developed for less than $10 million," Adam Kobeissi, the founder of market evaluation publication The Kobeissi Letter, said on X on Monday. Does DeepSeek help multiple languages? GPU: Minimum: NVIDIA A100 (80GB) with FP8/BF16 precision help. The AI's pure language capabilities and multilingual help have remodeled how I teach. Furthermore, its open-supply nature allows builders to combine AI into their platforms without the utilization restrictions that proprietary methods usually have.
That said, you can entry uncensored, US-primarily based variations of DeepSeek by way of platforms like Perplexity. Cloud Platform Access : If deploying on AWS, GCP, or Azure, having an energetic account on any of those platforms will assist with palms-on learning. You will learn to deploy, manage, and optimize these powerful models across various cloud platforms, including AWS, GCP, and Azure. Humans, including high gamers, want a number of practice and training to become good at chess. On January 27, 2025, major tech corporations, together with Microsoft, Meta, Nvidia, and Alphabet, collectively lost over $1 trillion in market value. This article explores the true-world purposes of DeepSeek’s technologies whereas clarifying misconceptions concerning the DEEPSEEKAI token that exists within the crypto market however is unaffiliated with the corporate. DeepSeek was founded lower than 2 years ago, has 200 employees, and was developed for less than $10 million," Adam Kobeissi, the founder of market evaluation publication The Kobeissi Letter, said on X on Monday. Does DeepSeek help multiple languages? GPU: Minimum: NVIDIA A100 (80GB) with FP8/BF16 precision help. The AI's pure language capabilities and multilingual help have remodeled how I teach. Furthermore, its open-supply nature allows builders to combine AI into their platforms without the utilization restrictions that proprietary methods usually have.
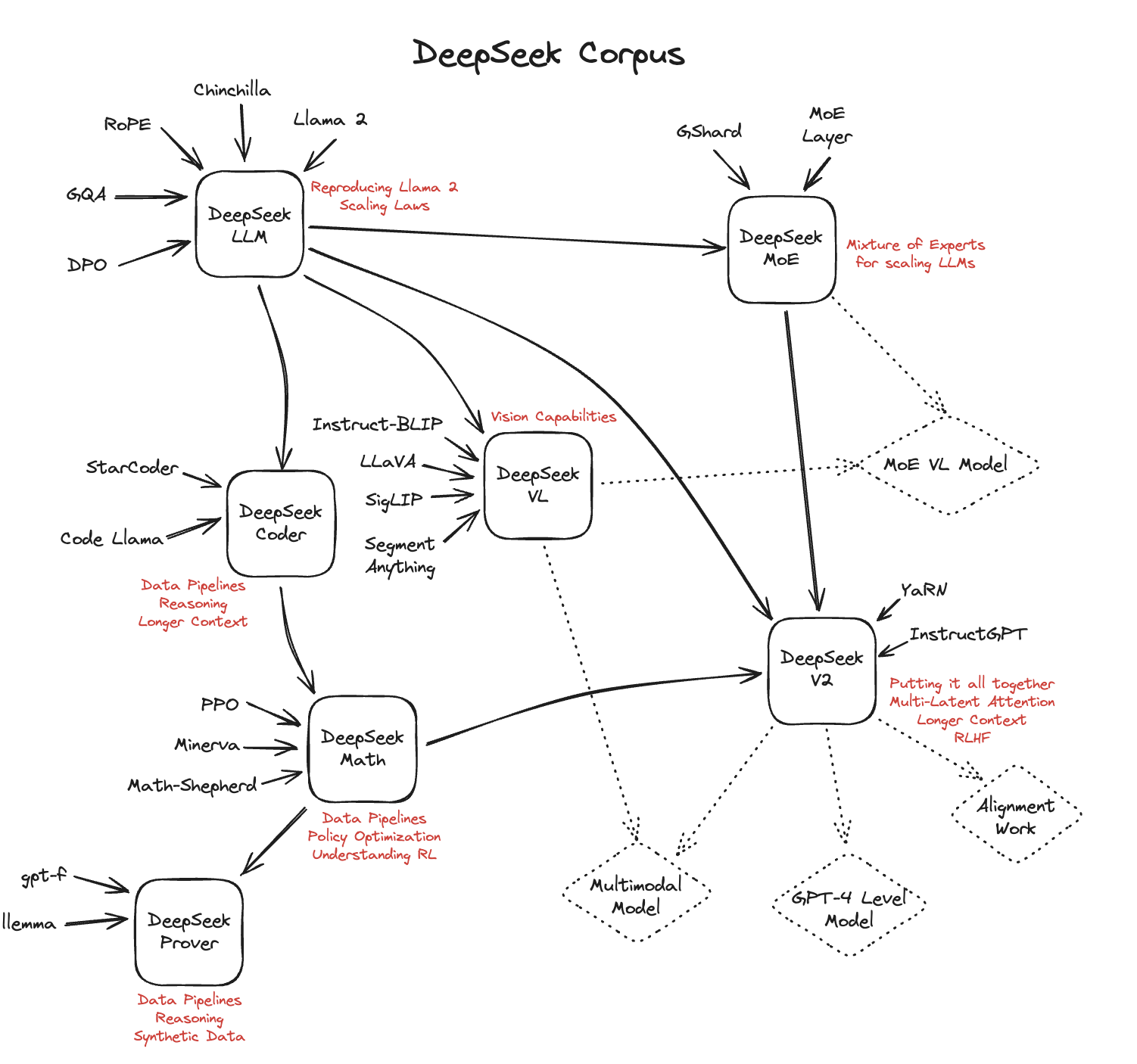 Basic Computer Skills: Familiarity with utilizing a command line interface (CLI) and navigating cloud platforms is beneficial. As half of a larger effort to improve the standard of autocomplete we’ve seen DeepSeek-V2 contribute to both a 58% enhance within the variety of accepted characters per user, in addition to a discount in latency for both single (76 ms) and multi line (250 ms) ideas. Unlike most groups that relied on a single mannequin for the competition, we utilized a twin-mannequin strategy. It is possible that the model has not been trained on chess data, and it is not able to play chess due to that. It is usually doable that the reasoning strategy of DeepSeek v3-R1 is just not suited to domains like chess. How a lot knowledge is needed to train DeepSeek-R1 on chess knowledge is also a key question. Alternatively, and as a follow-up of prior factors, a very exciting research path is to prepare DeepSeek-like fashions on chess information, in the identical vein as documented in DeepSeek-R1, and to see how they'll perform in chess. It is an thrilling time, and there are a number of research instructions to discover.
Basic Computer Skills: Familiarity with utilizing a command line interface (CLI) and navigating cloud platforms is beneficial. As half of a larger effort to improve the standard of autocomplete we’ve seen DeepSeek-V2 contribute to both a 58% enhance within the variety of accepted characters per user, in addition to a discount in latency for both single (76 ms) and multi line (250 ms) ideas. Unlike most groups that relied on a single mannequin for the competition, we utilized a twin-mannequin strategy. It is possible that the model has not been trained on chess data, and it is not able to play chess due to that. It is usually doable that the reasoning strategy of DeepSeek v3-R1 is just not suited to domains like chess. How a lot knowledge is needed to train DeepSeek-R1 on chess knowledge is also a key question. Alternatively, and as a follow-up of prior factors, a very exciting research path is to prepare DeepSeek-like fashions on chess information, in the identical vein as documented in DeepSeek-R1, and to see how they'll perform in chess. It is an thrilling time, and there are a number of research instructions to discover.
From my private perspective, it might already be incredible to succeed in this stage of generalization, and we aren't there yet (see next point). "Much of the brand new AI coins, AI agentic coins, and AI blockchains are nothing extra than just meme coins with no actual worth," University of Oxford researcher Dr. Petar Radanliev advised Decrypt. Taiwan, which faces a real risk of a quarantine or blockade, is more than 95 p.c reliant on seaborne power imports. The license exemption class created and applied to Chinese reminiscence agency XMC raises even larger threat of giving rise to domestic Chinese HBM production. Trying a brand new factor this week giving you fast China AI policy updates led by Bitwise. This approach has, for many reasons, led some to believe that fast developments may scale back the demand for prime-finish GPUs, impacting firms like Nvidia. DeepSeek-V2. Released in May 2024, that is the second version of the company's LLM, focusing on robust performance and lower coaching costs. 4x linear scaling, with 1k steps of 16k seqlen training.
The mannequin is a "reasoner" mannequin, and it tries to decompose/plan/purpose about the problem in different steps before answering. DeepSeek-R1 already reveals nice guarantees in lots of duties, and it is a really exciting model. The Free DeepSeek r1 story shows that China all the time had the indigenous capability to push the frontier in LLMs, but simply needed the suitable organizational structure to flourish. It is rather unclear what is the suitable approach to do it. Sounds futuristic, right? But that’s exactly the kind of challenge researchers are tackling at present. Understanding of AI & LLMs : Some information of massive language models and AI concepts may be useful but shouldn't be necessary. This complete course is designed to equip builders, AI fans, and enterprise teams with the talents needed to grasp massive language models (LLMs) corresponding to DeepSeek, LLaMA, Mistral, Gemma, and Qwen utilizing Open-WebUI and Ollama. It begins with an overview of Open-WebUI and Ollama, introducing their intuitive interfaces and real-time capabilities. It will also be the case that the chat mannequin just isn't as sturdy as a completion model, however I don’t suppose it's the main reason. ➤ Eliminates redundant steps: rely on the DeepSeek AI model for rapid data interpretation.
In the event you loved this information and you would like to receive more details concerning DeepSeek Chat please visit the web page.
- 이전글Hip Hop Jewelry Styles 25.03.02
- 다음글Where Can You Find The Top Black Leather Recliner Information? 25.03.02
댓글목록
등록된 댓글이 없습니다.