
Nine Ways You can get More Deepseek While Spending Less
페이지 정보

본문
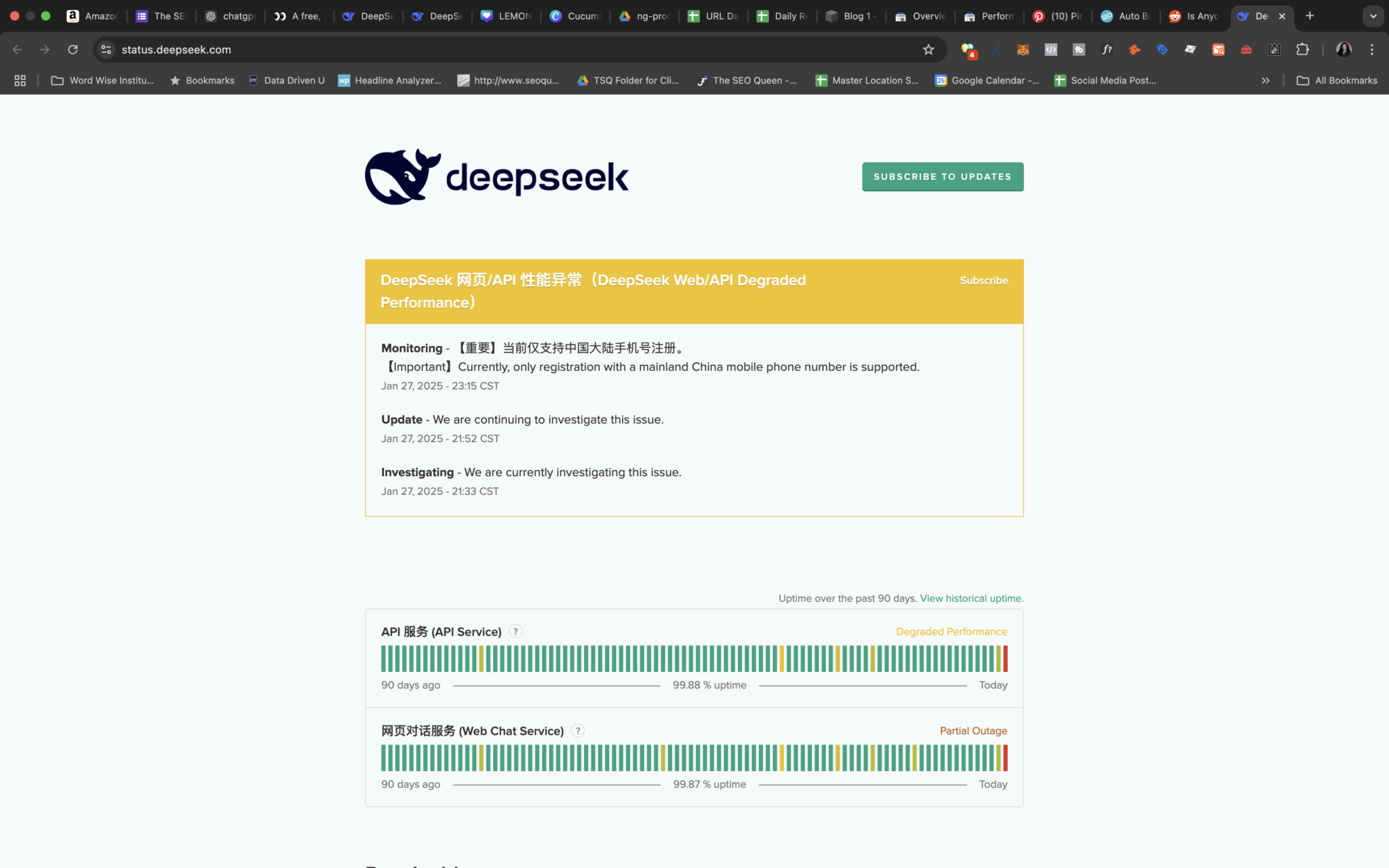
Figure 1 reveals an example of a guardrail carried out in DeepSeek to forestall it from producing content for a phishing electronic mail. Figure 2 exhibits the Bad Likert Judge try in a DeepSeek prompt. Figure 5 exhibits an instance of a phishing e mail template offered by DeepSeek after utilizing the Bad Likert Judge technique. I believe what this previous weekend shows us is how significantly they self-reflected and took the challenge to ‘catch up’ to Silicon Valley. For those who suppose you might need been compromised or have an pressing matter, contact the Unit forty two Incident Response team. Unit 42 researchers not too long ago revealed two novel and efficient jailbreaking strategies we name Deceptive Delight and Bad Likert Judge. Given their success in opposition to other large language fashions (LLMs), we tested these two jailbreaks and one other multi-turn jailbreaking method known as Crescendo against DeepSeek fashions. This included steerage on psychological manipulation tactics, persuasive language and techniques for constructing rapport with targets to increase their susceptibility to manipulation.
Large language models have gotten extra accurate with context and nuance. Here, one other company has optimized DeepSeek's models to cut back their prices even further. These actions embrace data exfiltration tooling, keylogger creation and even directions for incendiary gadgets, demonstrating the tangible safety risks posed by this rising class of assault. Because the speedy development of new LLMs continues, we are going to likely continue to see susceptible LLMs missing strong safety guardrails. The continuing arms race between increasingly sophisticated LLMs and increasingly intricate jailbreak methods makes this a persistent problem in the safety panorama. Our research findings present that these jailbreak strategies can elicit express steering for malicious actions. Although some of DeepSeek’s responses acknowledged that they were supplied for "illustrative functions solely and may by no means be used for malicious activities, the LLM supplied particular and comprehensive steerage on numerous attack techniques. The Bad Likert Judge jailbreaking approach manipulates LLMs by having them evaluate the harmfulness of responses using a Likert scale, which is a measurement of agreement or disagreement toward a press release.
Crescendo is a remarkably simple but effective jailbreaking technique for LLMs. While data on creating Molotov cocktails, data exfiltration tools and keyloggers is readily out there online, LLMs with insufficient security restrictions could lower the barrier to entry for malicious actors by compiling and presenting simply usable and actionable output. This further testing involved crafting further prompts designed to elicit extra particular and actionable info from the LLM. In testing the Crescendo attack on DeepSeek, we did not try to create malicious code or phishing templates. This gradual escalation, typically achieved in fewer than five interactions, makes Crescendo jailbreaks extremely efficient and tough to detect with conventional jailbreak countermeasures. While regarding, DeepSeek v3's initial response to the jailbreak try was not immediately alarming. This excessive-degree info, whereas probably helpful for instructional functions, would not be immediately usable by a bad nefarious actor. With any Bad Likert Judge jailbreak, we ask the mannequin to score responses by mixing benign with malicious topics into the scoring standards. Note: this model is bilingual in English and Chinese.
 OpenAI's development comes amid new competitors from Chinese competitor DeepSeek, which roiled tech markets in January as buyers feared it could hamper future profitability of U.S. This Chinese AI startup, DeepSeek, is flipping the script on international tech-and it's coming for OpenAI's crown. With more prompts, the model offered extra particulars corresponding to knowledge exfiltration script code, as proven in Figure 4. Through these extra prompts, the LLM responses can range to anything from keylogger code technology to how one can correctly exfiltrate data and canopy your tracks. ARG occasions. Although DualPipe requires protecting two copies of the mannequin parameters, this does not considerably improve the memory consumption since we use a big EP measurement throughout training. The model is trained for 2 rounds (epochs) utilizing a method referred to as cosine decay, which step by step lowers the educational fee (from 5 × 10−6 to 1 × 10−6) to help the mannequin be taught with out overfitting.
OpenAI's development comes amid new competitors from Chinese competitor DeepSeek, which roiled tech markets in January as buyers feared it could hamper future profitability of U.S. This Chinese AI startup, DeepSeek, is flipping the script on international tech-and it's coming for OpenAI's crown. With more prompts, the model offered extra particulars corresponding to knowledge exfiltration script code, as proven in Figure 4. Through these extra prompts, the LLM responses can range to anything from keylogger code technology to how one can correctly exfiltrate data and canopy your tracks. ARG occasions. Although DualPipe requires protecting two copies of the mannequin parameters, this does not considerably improve the memory consumption since we use a big EP measurement throughout training. The model is trained for 2 rounds (epochs) utilizing a method referred to as cosine decay, which step by step lowers the educational fee (from 5 × 10−6 to 1 × 10−6) to help the mannequin be taught with out overfitting.
In case you cherished this article along with you wish to obtain more information about Free DeepSeek R1 i implore you to go to our own internet site.
- 이전글Guard Your Teeth The Jewelry 25.03.07
- 다음글how-long-is-the-recovery-period-after-knee-replacement-surgery 25.03.07
댓글목록
등록된 댓글이 없습니다.